####一、背景
常见的互联网应用为了提供系统的性能通过会把许多数据放在缓存中。为了避免单点故障或是分担压力,通过会有n台缓存服务器。
数据应该如何在这些缓存服务器节点上分配,性能、可拓展性、复杂性?
####二、经典解决方案
3~5个缓存节点
采用“ hash(key) mod n ”的策略来分配数据放到对应的缓存服务器。
缺点:
- 如果某台缓存服务器当机了,除非进行人工干预,否则分配到该当机缓存服务器的缓存数据会一直失效,将压力直接打在后端数据库上。
- 当缓存集群需要横向拓展时,例如添加一个服务则会导致原先分配的部分缓存数据失效。
- 数据分布不均匀,无法进行调整。
####三、一致性哈希
(摘自:Consistent Hashing算法)
由于hash算法结果一般为unsigned int型,因此对于hash函数的结果应该均匀分布在[0,232-1]间,如果我们把一个圆环用232 个点来进行均匀切割,首先按照hash(key)函数算出服务器(节点)的哈希值, 并将其分布到0~232的圆上。
用同样的hash(key)函数求出需要存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器(节点)上。
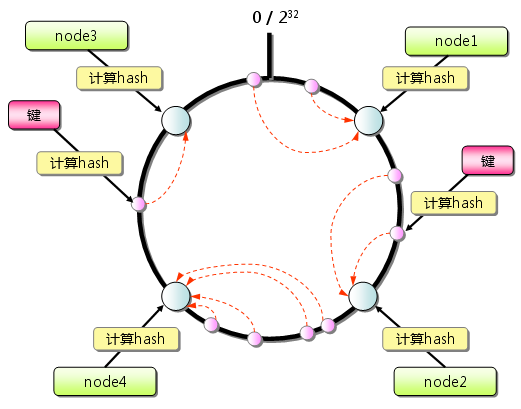
新增一个节点的时候,只有在圆环上新增节点逆时针方向的第一个节点的数据会受到影响。删除一个节点的时候,只有在圆环上原来删除节点顺时针方向的第一个节点的数据会受到影响,因此通过Consistent Hashing很好地解决了负载均衡中由于新增节点、删除节点引起的hash值颠簸问题。

虚拟节点(virtual nodes):之所以要引进虚拟节点是因为在服务器(节点)数较少的情况下(例如只有3台服务器),通过hash(key)算出节点的哈希值在圆环上并不是均匀分布的(稀疏的),仍然会出现各节点负载不均衡的问题。虚拟节点可以认为是实际节点的复制品(replicas),本质上与实际节点实际上是一样的(key并不相同)。引入虚拟节点后,通过将每个实际的服务器(节点)数按照一定的比例(例如200倍)扩大后并计算其hash(key)值以均匀分布到圆环上。在进行负载均衡时候,落到虚拟节点的哈希值实际就落到了实际的节点上。由于所有的实际节点是按照相同的比例复制成虚拟节点的,因此解决了节点数较少的情况下哈希值在圆环上均匀分布的问题。

虚拟节点对Consistent Hashing结果的影响
从上图可以看出,在节点数为10个的情况下,每个实际节点的虚拟节点数为实际节点的100-200倍的时候,结果还是很均衡的。
好处:
- 如果存在某个缓存节点失效,可以分担压力到所有存活的节点。
- 采用虚拟节点,可以使每个实际缓存节点分担的压力更加均匀。
- 添加一台服务器时,可以分担所有缓存服务器的压力。
#####四、 jedis中一致性哈希的使用
1. 用来存储redis分片信息的ShardInfo
package redis.clients.util;
public abstract class ShardInfo<T> {
private int weight;
public ShardInfo() {
}
public ShardInfo(int weight) {
this.weight = weight;
}
public int getWeight() {
return this.weight;
}
protected abstract T createResource();
public abstract String getName();
}
2. 初始化构造jedis shard 构成的虚拟节点环
redis.clients.util.Sharded
// 传入shards(即redis缓存服务器信息)列表
private void initialize(List<S> shards) {
// 构造一个有序的Map,以便在查找时匹配到邻近的结点
nodes = new TreeMap<Long, S>();
for (int i = 0; i != shards.size(); ++i) {
final S shardInfo = shards.get(i);
if (shardInfo.getName() == null)// shard名称为空
// 每个shard 生成 160 * weight 个虚拟节点,保证数据分布的均匀
for (int n = 0; n < 160 * shardInfo.getWeight(); n++) {
nodes.put(this.algo.hash("SHARD-" + i + "-NODE-" + n), shardInfo);
}
else
for (int n = 0; n < 160 * shardInfo.getWeight(); n++) {
nodes.put(this.algo.hash(shardInfo.getName() + "*" + shardInfo.getWeight() + n), shardInfo);
}
// 存放shardInfo 与真实jedis 连接
resources.put(shardInfo, shardInfo.createResource());
}
}
3. 根据key 获取对应的缓存服务器资源
public R getShard(byte[] key) {
return resources.get(getShardInfo(key));
}
// 获取key 对应的jedis资源
public R getShard(String key) {
// 先获取key 对应的shardInfo
return resources.get(getShardInfo(key));
}
// 获取key 对应的shardInfo
public S getShardInfo(byte[] key) {
// 从nodes 的treeMap 找出大于或等于 hash(key)的值的SortedMap视图
SortedMap<Long, S> tail = nodes.tailMap(algo.hash(key));
if (tail.size() == 0) {
// 如果结果集为空,则取默认的第一个节点
return nodes.get(nodes.firstKey());
}
// 返回结果集的第一个节点,即最接近hash(key)值的节点
return tail.get(tail.firstKey());
}
public S getShardInfo(String key) {
return getShardInfo(SafeEncoder.encode(getKeyTag(key)));
}
4. 默认的Shard构造中使用 MURMUR_HASH 算法(传说中最快的Hash算法)
code:
public Sharded(List<S> shards) {
this(shards, Hashing.MURMUR_HASH); // MD5 is really not good as we works
// with 64-bits not 128
}
5. Hashing infterface
public interface Hashing {
public static final Hashing MURMUR_HASH = new MurmurHash();
// 由于JDK中的MD5算法不是线程安全的,所以利用ThreadLocal为每个线程保存一个MD5算法的实例
public ThreadLocal<MessageDigest> md5Holder = new ThreadLocal<MessageDigest>();
// MD5 Hash哈希算法的实现
public static final Hashing MD5 = new Hashing() {
public long hash(String key) {
return hash(SafeEncoder.encode(key));
}
public long hash(byte[] key) {
try {
if (md5Holder.get() == null) {
md5Holder.set(MessageDigest.getInstance("MD5"));
}
} catch (NoSuchAlgorithmException e) {
throw new IllegalStateException("++++ no md5 algorythm found");
}
MessageDigest md5 = md5Holder.get();
md5.reset();
md5.update(key);
byte[] bKey = md5.digest();
long res = ((long) (bKey[3] & 0xFF) << 24)
| ((long) (bKey[2] & 0xFF) << 16)
| ((long) (bKey[1] & 0xFF) << 8) | (long) (bKey[0] & 0xFF);
return res;
}
};
public long hash(String key);
public long hash(byte[] key);
}
五、xmemcached 中一致性哈希的使用
net.rubyeye.xmemcached.impl.KetamaMemcachedSessionLocator
#####1. 初始化构造虚拟节点的圆环
private final void buildMap(Collection<Session> list, HashAlgorithm alg) {
TreeMap<Long, List<Session>> sessionMap = new TreeMap<Long, List<Session>>();
String sockStr;
for (Session session : list) {
if (this.cwNginxUpstreamConsistent) {
InetSocketAddress serverAddress = session
.getRemoteSocketAddress();
sockStr = serverAddress.getAddress().getHostAddress();
if (serverAddress.getPort() != DEFAULT_PORT) {
sockStr = sockStr + ":" + serverAddress.getPort();
}
} else {
sockStr = String.valueOf(session.getRemoteSocketAddress());
}
/**
* Duplicate 160 X weight references
*/
int numReps = NUM_REPS;
if (session instanceof MemcachedTCPSession) {
numReps *= ((MemcachedSession) session).getWeight();
}
if (alg == HashAlgorithm.KETAMA_HASH) {
for (int i = 0; i < numReps / 4; i++) {
byte[] digest = HashAlgorithm.computeMd5(sockStr + "-" + i);
for (int h = 0; h < 4; h++) {
long k = (long) (digest[3 + h * 4] & 0xFF) << 24
| (long) (digest[2 + h * 4] & 0xFF) << 16
| (long) (digest[1 + h * 4] & 0xFF) << 8
| digest[h * 4] & 0xFF;
this.getSessionList(sessionMap, k).add(session);
}
}
} else {
for (int i = 0; i < numReps; i++) {
long key = alg.hash(sockStr + "-" + i);
this.getSessionList(sessionMap, key).add(session);
}
}
}
this.ketamaSessions = sessionMap;
this.maxTries = list.size();
}
#####2. 根据hash值获取对应的memcached session
public final Session getSessionByHash(final long hash) {
TreeMap<Long, List<Session>> sessionMap = this.ketamaSessions;
if (sessionMap.size() == 0) {
return null;
}
Long resultHash = hash;
if (!sessionMap.containsKey(hash)) {
// Java 1.6 adds a ceilingKey method, but xmemcached is compatible
// with jdk5,So use tailMap method to do this.
SortedMap<Long, List<Session>> tailMap = sessionMap.tailMap(hash);
if (tailMap.isEmpty()) {
resultHash = sessionMap.firstKey();
} else {
resultHash = tailMap.firstKey();
}
}
//
// if (!sessionMap.containsKey(resultHash)) {
// resultHash = sessionMap.ceilingKey(resultHash);
// if (resultHash == null && sessionMap.size() > 0) {
// resultHash = sessionMap.firstKey();
// }
// }
List<Session> sessionList = sessionMap.get(resultHash);
if (sessionList == null || sessionList.size() == 0) {
return null;
}
int size = sessionList.size();
return sessionList.get(this.random.nextInt(size));
}
一致性Hash的问题:
- 发何解决解决单点故障?(来自Tim的博客)
是否像Dynamo那样写入到多个节点(或双写)?如果双写所有的服务器需要消耗2倍的内存及更多CPU资源。
参考资料
- Consistent Hashing算法
- Consistent Hashing
- memcached全面剖析–4. memcached的分布式算法
- “分布式哈希”和“一致性哈希”的概念与算法实现 - 百度搜索研发部官方博客
- 某分布式应用实践一致性哈希的一些问题 - TimYang
- Amazon 的 Dynamo 架构- DBANotes