####一、简介
thrift 是facebook 开源的跨语言、可扩展的RPC框架,实现了完整的软件栈,包括利用生成代码的引擎来构建高效的服务,支持C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, OCaml , Delphi 等语言。
thrift 类似ICE、Protobuf 等框架,使用后缀名为.thrift 的 接口定义(interface definition)文件来定义thrift 的数据结构与服务接口。定义的服务接口由服务端实现,可以被客户端所调用。可以根据你所使用的语言,生成相应的代码文件。使用如下命令生成:
thrift --gen <language> <Thrift filename>
####二、thrift 架构
thrift = RPC + Serialization,类似于Java的Hession 或RMI,不过thrift支持跨语言。
根据接口定义文件,可以根据不同的语言生成不同的的基础代码,来快速构建跨语言的分布式服务。
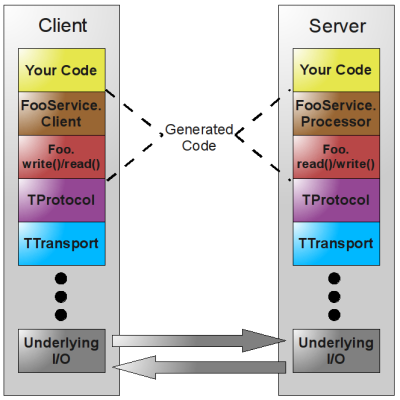
thrift 层次
- Your Code: 你的业务代码,具体服务实现的业务逻辑
- FooService.Client/ FooService.Processor: 是thrift 生成的代码,我们通过访问生成的Client来实现远程RPC调用,通过实现 定义中的接口,而成为一个Processor 的具体处理类。
- Foo.write()/read(): 根据定义的结构体来向协议层TProtocol 读出或写入数据,相当于实现 对象的序列化与反序列化。
- TProtocol:传输协议层
- TTransport: 传输层
- Underlying I/O: 底层IO
引用官方的层次图 http://thrift.apache.org/docs/concepts/
+-------------------------------------------+
| Server |
| (single-threaded, event-driven etc) |
+-------------------------------------------+
| Processor |
| (compiler generated) |
+-------------------------------------------+
| Protocol |
| (JSON, compact etc) |
+-------------------------------------------+
| Transport |
| (raw TCP, HTTP etc) |
+-------------------------------------------+
#####Transport
TTransport层提供对网络IO读取或写入的简单封装,能够让thrift 与系统其它部分解耦。
Transport 的接口
- open
- close
- read
- write
- flush
在Transport 的基础上,thrift 在服务端使用ServerTransport为新建立的连接创建原始传输对象。
ServerTransport的接口
传输层的类型
- TSocket- 使用堵塞式I/O进行传输,也是最常见的模式。
- TFramedTransport- 使用非阻塞方式,按块的大小,进行传输,类似于Java中的NIO。
- TFileTransport- 顾名思义按照文件的方式进程传输,虽然这种方式不提供Java的实现,但是实现起来非常简单。
- TMemoryTransport- 使用内存I/O,就好比Java中的ByteArrayOutputStream实现。
- TZlibTransport- 使用执行zlib压缩,不提供Java的实现。
#####Protocol
TProtocol传输协议用来指定数据序列化的格式,例如JSON,XML或是压缩的二进流等。
TProtocol接口定义:
writeMessageBegin(name, type, seq)
writeMessageEnd()
writeStructBegin(name)
writeStructEnd()
writeFieldBegin(name, type, id)
writeFieldEnd()
writeFieldStop()
writeMapBegin(ktype, vtype, size)
writeMapEnd()
writeListBegin(etype, size)
writeListEnd()
writeSetBegin(etype, size)
writeSetEnd()
writeBool(bool)
writeByte(byte)
writeI16(i16)
writeI32(i32)
writeI64(i64)
writeDouble(double)
writeString(string)
name, type, seq = readMessageBegin()
readMessageEnd()
name = readStructBegin()
readStructEnd()
name, type, id = readFieldBegin()
readFieldEnd()
k, v, size = readMapBegin()
readMapEnd()
etype, size = readListBegin()
readListEnd()
etype, size = readSetBegin()
readSetEnd()
bool = readBool()
byte = readByte()
i16 = readI16()
i32 = readI32()
i64 = readI64()
double = readDouble()
string = readString()
传输协议的类型:
- TBinaryProtocol – 二进制编码格式进行数据传输。
- TCompactProtocol – 这种协议非常有效的,使用Variable-Length Quantity (VLQ) 编码对数据进行压缩。
- TJSONProtocol – 使用JSON的数据编码协议进行数据传输。
- TSimpleJSONProtocol – 这种节约只提供JSON只写的协议,适用于通过脚本语言解析
- TDebugProtocol – 在开发的过程中帮助开发人员调试用的,以文本的形式展现方便阅读。
#####Scheme
Scheme 实现序列化、反序列化的接口中。每个Thrift对象(包括输入参数、返回值)都实现该方法,从而达到序列化到指定的协议中去,或者从指定的协议中读出对象。
public interface IScheme<T extends TBase> {
public void read(org.apache.thrift.protocol.TProtocol iproto, T struct) throws org.apache.thrift.TException;
public void write(org.apache.thrift.protocol.TProtocol oproto, T struct) throws org.apache.thrift.TException;
}
public interface SchemeFactory {
public <S extends IScheme> S getScheme();
}
public abstract class StandardScheme<T extends TBase> implements IScheme<T> {
}
#####Processor
Processor 用来服务端收到请求后,对传入的数据进行读取后,再写入到输出中。具体就是在服务端收到数据包后,根据输入协议TProtocol in 读取相应请求的方法和参数,调用具体实现服务的业务逻辑后,再将返回的结果写入TProtocol out中。
interface TProcessor {
bool process(TProtocol in, TProtocol out) throws TException
}
Processor 由代码生成器根据不同的语言环境生成。
#####Server 服务端
Server的处理流程如下
- 创建一个服务端的传输transport
- 创建用来输入和输出的transport
- 创建基于传输协议protocol 上的processor(代理到相应的业务方法)
- 等待客户端连接,并把请求转发给processor
服务端类型
- TSimpleServer 单线程服务器端使用标准的堵塞式I/O。
- TThreadPoolServer 多线程服务器端使用标准的堵塞式I/O。
- TNonblockingServer – 多线程服务器端使用非堵塞式I/O,并且实现了Java中的NIO通道。
- THsHaServer -(半同步/半异步的server)就应运而生了。它使用一个单独的线程来处理网络I/O,一个独立的worker线程池来处理消息。
- TThreadedSelectorServer允许你用多个线程来处理网络I/O。它维护了两个线程池,一个用来处理网络I/O,另一个用来进行请求的处理。
三、利用thrift文件生成java环境的文件
thrift服务接口定义文件
// usage
// for java:
// cd ${project_path}
// thrift -gen java -out ./src/main/java ./src/main/thrift/user.thrift
namespace java com.cjf.practice // 指定生成java 文件的包名
namespace py com.cjf.practice
const string VERSION = "1.0.0" // 定义一个常量(非必须)
// 定义一个结构体,相当于Java中的领域对象
struct UserProfile {
1: i32 uid,
2: string name,
3: string blurb
}
// 定义服务接口
service UserStorage {
void store(1: UserProfile user),
UserProfile retrieve(1: i32 uid)
}
接口定义文件具体支持的类型与结构,请参考官网 Thrift interface description language。
生成UserProfile.java 文件类似Protobuf 生成的对象文件。
public class UserProfile implements org.apache.thrift.TBase<UserProfile, UserProfile._Fields>, java.io.Serializable, Cloneable {
private static final org.apache.thrift.protocol.TStruct STRUCT_DESC = new org.apache.thrift.protocol.TStruct("UserProfile");
private static final org.apache.thrift.protocol.TField UID_FIELD_DESC = new org.apache.thrift.protocol.TField("uid", org.apache.thrift.protocol.TType.I32, (short)1);
private static final org.apache.thrift.protocol.TField NAME_FIELD_DESC = new org.apache.thrift.protocol.TField("name", org.apache.thrift.protocol.TType.STRING, (short)2);
private static final org.apache.thrift.protocol.TField BLURB_FIELD_DESC = new org.apache.thrift.protocol.TField("blurb", org.apache.thrift.protocol.TType.STRING, (short)3);
private static final Map<Class<? extends IScheme>, SchemeFactory> schemes = new HashMap<Class<? extends IScheme>, SchemeFactory>();
static {
schemes.put(StandardScheme.class, new UserProfileStandardSchemeFactory());
schemes.put(TupleScheme.class, new UserProfileTupleSchemeFactory());
}
public int uid; // required
public String name; // required
public String blurb; // required
/** The set of fields this struct contains, along with convenience methods for finding and manipulating them. */
public enum _Fields implements org.apache.thrift.TFieldIdEnum {
UID((short)1, "uid"),
NAME((short)2, "name"),
BLURB((short)3, "blurb");
private static final Map<String, _Fields> byName = new HashMap<String, _Fields>();
static {
for (_Fields field : EnumSet.allOf(_Fields.class)) {
byName.put(field.getFieldName(), field);
}
}
/**
* Find the _Fields constant that matches fieldId, or null if its not found.
*/
public static _Fields findByThriftId(int fieldId) {
switch(fieldId) {
case 1: // UID
return UID;
case 2: // NAME
return NAME;
case 3: // BLURB
return BLURB;
default:
return null;
}
}
...
生成的服务接口文件UserStorage:
######1. 第1部分是服务接口的定义:
public class UserStorage {
public interface Iface {
public void store(UserProfile user) throws org.apache.thrift.TException;
public UserProfile retrieve(int uid) throws org.apache.thrift.TException;
}
public interface AsyncIface {
public void store(UserProfile user, org.apache.thrift.async.AsyncMethodCallback<AsyncClient.store_call> resultHandler) throws org.apache.thrift.TException;
public void retrieve(int uid, org.apache.thrift.async.AsyncMethodCallback<AsyncClient.retrieve_call> resultHandler) throws org.apache.thrift.TException;
}
######2. 第2部分同步和异步接口的Client实现:
public static class Client extends org.apache.thrift.TServiceClient implements Iface {
public static class Factory implements org.apache.thrift.TServiceClientFactory {
public Factory() {}
public Client getClient(org.apache.thrift.protocol.TProtocol prot) {
return new Client(prot);
}
public Client getClient(org.apache.thrift.protocol.TProtocol iprot, org.apache.thrift.protocol.TProtocol oprot) {
return new Client(iprot, oprot);
}
}
….
public static class AsyncClient extends org.apache.thrift.async.TAsyncClient implements AsyncIface {
public static class Factory implements org.apache.thrift.async.TAsyncClientFactory<AsyncClient> {
private org.apache.thrift.async.TAsyncClientManager clientManager;
private org.apache.thrift.protocol.TProtocolFactory protocolFactory;
public Factory(org.apache.thrift.async.TAsyncClientManager clientManager, org.apache.thrift.protocol.TProtocolFactory protocolFactory) {
this.clientManager = clientManager;
this.protocolFactory = protocolFactory;
}
public AsyncClient getAsyncClient(org.apache.thrift.transport.TNonblockingTransport transport) {
return new AsyncClient(protocolFactory, clientManager, transport);
}
}
######3. 第3部分就是生成Processor:
public static class Processor<I extends Iface> extends org.apache.thrift.TBaseProcessor<I> implements org.apache.thrift.TProcessor {
private static final Logger LOGGER = LoggerFactory.getLogger(Processor.class.getName());
public Processor(I iface) {
super(iface, getProcessMap(new HashMap<String, org.apache.thrift.ProcessFunction<I, ? extends org.apache.thrift.TBase>>()));
}
protected Processor(I iface, Map<String, org.apache.thrift.ProcessFunction<I, ? extends org.apache.thrift.TBase>> processMap) {
super(iface, getProcessMap(processMap));
}
可以看到Processor需要传入Iface接口的实现作为构造函数的参数,并且继承于TBaseProcessor类。
private static <I extends Iface> Map<String, org.apache.thrift.ProcessFunction<I, ? extends org.apache.thrift.TBase>> getProcessMap(Map<String, org.apache.thrift.ProcessFunction<I, ? extends org.apache.thrift.TBase>> processMap) {
processMap.put("store", new store());
processMap.put("retrieve", new retrieve());
return processMap;
}
这里的processMap就是具体的业务方法对象,每个业务方法都是一个ProcessFunction对象,会被TBaseProcessor中被调用。TBaseProcessor是所有生成的所有Processor 的父类。
在TBaseProcessor中,我们可以看到Processor的处理流程。
@Override
public boolean process(TProtocol in, TProtocol out) throws TException {
TMessage msg = in.readMessageBegin();
// 根据msg.name 获取相应的ProcessFunction
ProcessFunction fn = processMap.get(msg.name);
if (fn == null) {
TProtocolUtil.skip(in, TType.STRUCT);
in.readMessageEnd();
TApplicationException x = new TApplicationException(TApplicationException.UNKNOWN_METHOD, "Invalid method name: '"+msg.name+"'");
out.writeMessageBegin(new TMessage(msg.name, TMessageType.EXCEPTION, msg.seqid));
x.write(out);
out.writeMessageEnd();
out.getTransport().flush();
return true;
}
fn.process(msg.seqid, in, out, iface);
return true;
}
四、实现完整的示例(服务端和客户端均采用阻塞IO传输的Transport)
服务实现类
public class UserStorageServiceImpl implements Iface{
private static Map<Integer, UserProfile> userMap = new HashMap<Integer, UserProfile>();
@Override
public void store(UserProfile user) throws TException {
userMap.put(user.getUid(), user);
}
@Override
public UserProfile retrieve(int uid) throws TException {
return userMap.get(uid);
}
}
创建一个阻塞式(Blocking)Socket的多线程的Server
public class SyncUserStorageServer {
public static void main(String[] args) throws TTransportException {
int port = 8600;
TServerSocket serverTransport = new TServerSocket(port);
Factory portFactory = new TBinaryProtocol.Factory(true, true);
TProcessor processor = new UserStorage.Processor<UserStorageServiceImpl>(new UserStorageServiceImpl());
TThreadPoolServer.Args serverArgs = new TThreadPoolServer.Args(serverTransport);
serverArgs.processor(processor);
serverArgs.protocolFactory(portFactory);
TThreadPoolServer server = new TThreadPoolServer(serverArgs);
server.serve();
}
}
客户端的同步调用代码
public class UserStorageClient {
public static void main(String[] args) throws TException, IOException {
TTransport transport = new TSocket("localhost", 8600);
TBinaryProtocol binaryProtocol = new TBinaryProtocol(transport);
UserStorage.Client client = new UserStorage.Client.Factory().getClient(binaryProtocol);
UserProfile user = new UserProfile(1, "user_name", "sth... i don't know");
transport.open();
System.out.println(user);
client.store(user);
System.out.println("store finished.");
UserProfile fetchUser = client.retrieve(user.getUid());
System.out.println(fetchUser);
System.out.println(user.equals(fetchUser));
transport.close();
}
}
五、服务端采用非阻塞式(Non-Blocking)传输的transport
######服务端
public class AsyncUserStorageServer {
public static void main(String[] args) throws TTransportException {
int port = 8600;
TNonblockingServerSocket serverTransport = new TNonblockingServerSocket(port);
Factory portFactory = new TBinaryProtocol.Factory(true, true);
TProcessor processor = new UserStorage.Processor<UserStorageServiceImpl>(new UserStorageServiceImpl());
TThreadedSelectorServer.Args serverArgs = new TThreadedSelectorServer.Args(serverTransport);
serverArgs.processor(processor);
serverArgs.protocolFactory(portFactory);
TThreadedSelectorServer server = new TThreadedSelectorServer(serverArgs);
server.serve();
}
}
异步调用的客户端(异步调用必须采用非阻塞式传输TNonblockingTransport)
public class AsyncUserStorageClient {
static final CountDownLatch countDownLatch = new CountDownLatch(1);
public static void main(String[] args) throws TException, IOException, InterruptedException {
TNonblockingTransport transport = new TNonblockingSocket("localhost", 8600);
TAsyncClientManager clientManager = new TAsyncClientManager();
TProtocolFactory protocolFactory = new TBinaryProtocol.Factory();
final UserStorage.AsyncClient client = new UserStorage.AsyncClient.Factory(clientManager, protocolFactory)
.getAsyncClient(transport);
final UserProfile user = new UserProfile(1, "user_name", "sth... i don't know");
System.out.println(user);
client.store(user, new AsyncMethodCallback<UserStorage.AsyncClient.store_call>() {
@Override
public void onError(Exception exception) {
System.out.println(exception.getMessage());
countDownLatch.countDown();
}
@Override
public void onComplete(store_call response) {
// TODO Auto-generated method stub
try {
System.out.println("store finished.");
step2(client, user);
} catch (TException e) {
e.printStackTrace();
}
}
});
countDownLatch.await();
}
private static void step2(UserStorage.AsyncClient client, final UserProfile user) throws TException {
client.retrieve(user.getUid(), new AsyncMethodCallback<UserStorage.AsyncClient.retrieve_call>() {
@Override
public void onError(Exception exception) {
// TODO Auto-generated method stub
countDownLatch.countDown();
}
@Override
public void onComplete(retrieve_call response) {
try {
UserProfile fetchUser = response.getResult();
System.out.println(fetchUser);
System.out.println(user.equals(fetchUser));
} catch (TException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
countDownLatch.countDown();
}
});
}
同步调用,但采用带缓存的网络IO(TFramedTransport)的客户端
public class SyncUserStorageClientForAsyncServer {
public static void main(String[] args) throws TException, IOException {
TTransport transport = new TFramedTransport(new TSocket("localhost", 8600));
TBinaryProtocol binaryProtocol = new TBinaryProtocol(transport);
UserStorage.Client client = new UserStorage.Client.Factory().getClient(binaryProtocol);
transport.open();
UserProfile user = new UserProfile(1, "user_name", "sth... i don't know");
System.out.println(user);
client.store(user);
System.out.println("store finished.");
UserProfile fetchUser = client.retrieve(user.getUid());
System.out.println(fetchUser);
System.out.println(user.equals(fetchUser));
transport.close();
}
}
六、服务端采用带缓存的TFramedTransport传输
public class FramedUserStorageServer {
public static void main(String[] args) throws TTransportException {
int port = 8600;
TServerTransport serverTransport = new TServerSocket(port);
Factory portFactory = new TBinaryProtocol.Factory(true, true);
TProcessor processor = new UserStorage.Processor<UserStorageServiceImpl>(new UserStorageServiceImpl());
TThreadPoolServer.Args serverArgs = new TThreadPoolServer.Args(serverTransport);
serverArgs.processor(processor);
serverArgs.protocolFactory(portFactory);
serverArgs.transportFactory(new TFramedTransport.Factory());
TThreadPoolServer server = new TThreadPoolServer(serverArgs);
server.serve();
}
}
相应的同步调用客户
public class SyncUserStorageClientForAsyncServer {
public static void main(String[] args) throws TException, IOException {
TTransport transport = new TFramedTransport(new TSocket("localhost", 8600));
TBinaryProtocol binaryProtocol = new TBinaryProtocol(transport);
UserStorage.Client client = new UserStorage.Client.Factory().getClient(binaryProtocol);
transport.open();
UserProfile user = new UserProfile(1, "user_name", "sth... i don't know");
System.out.println(user);
client.store(user);
System.out.println("store finished.");
UserProfile fetchUser = client.retrieve(user.getUid());
System.out.println(fetchUser);
System.out.println(user.equals(fetchUser));
transport.close();
}
}
可以支持异步调用的客户端。
小结:服务端网络传输有三种模式:BLOCKING, FRAMED, NONBLOCKING;服务端与客户端采用的transport 与协议要一致;客户端是否异步调用与服务端是否异步网络IO无关。
例子源码: https://github.com/sharewind/thrift-quick-start
参考资料