###NSQ Internals
NSQ内幕
NSQ is composed of 3 daemons:
NSQ 由3个守护进程组成:
nsqd is the daemon that receives, queues, and delivers messages to clients.
nsqd是接收、队列和传送 消息到客户端的守护进程
nsqlookupd is the daemon that manages topology information and provides an eventually consistent discovery service.
nsqlookupd是管理的拓扑信息,并提供了最终一致发现服务的守护进程。
nsqadmin is a web UI to introspect the cluster in realtime (and perform various administrative tasks).
nsqadmin是一个Web UI来实时监控集群(和执行各种管理任务)。
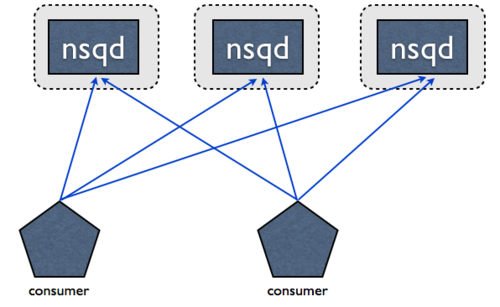
Data flow in NSQ is modeled as a tree of streams and consumers. A topic is a distinct stream of data. A channel is a logical grouping of consumers subscribed to a given topic.
在NSQ数据流建模为一个消息流和消费者的树。一个topic是一个独特的数据流。一个channel是消费者订阅了某个topic的逻辑分组。

A single nsqd can have many topics and each topic can have many channels. A channel receives a copy of all the messages for the topic, enabling multicast style delivery while each message on a channel is distributed amongst its subscribers, enabling load-balancing.
单个nsqd可以有很多的topic,每个topic可以有多channel。一个channel接收到一个topic中所有消息的副本,启用组播方式的传输,使消息同时在每个channel的所有订阅用户间分发,从而实现负载平衡。
These primitives form a powerful framework for expressing a variety of . simple and complex topologies
这些原语组成一个强大的框架,用于表示各种简单和复杂的拓扑结构。
For more information about the design of NSQ see the design doc.
有关NSQ的设计的更多信息请参见设计文档。
topics/channels
Topics and channels, the core primitives of NSQ, best exemplify how the design of the system translates seamlessly to the features of Go.
topics和channels,NSQ的核心基础,最能说明如何把go语言的特点无缝地转化为系统设计。
Go’s channels (henceforth referred to as “go-chan” for disambiguation) are a natural way to express queues, thus an NSQ topic/channel, at its core, is just a buffered go-chan of Message pointers. The size of the buffer is equal to the –mem-queue-size configuration parameter.
Go语言中的channel(为消除歧义以下简称为“go-chan”)是实现队列一种自然的方式,因此一个NSQ topic/channel,其核心,只是一个缓冲的go-chan Message指针。缓冲区的大小等于 –mem-queue-size 的配置参数。
After reading data off the wire, the act of publishing a message to a topic involves:
在懂了读数据后,发布消息到一个topic的行为涉及到:
- instantiation of a Message struct (and allocation of the message body []byte)
- read-lock to get the Topic
- read-lock to check for the ability to publish
- send on a buffered go-chan
To get messages from a topic to its channels the topic cannot rely on typical go-chan receive semantics, because multiple goroutines receiving on a go-chan would distribute the messages while the desired end result is to copy each message to every channel (goroutine).
从一个topic中的channel获取消息不能依赖于经典的 go-chan 语义,因为多个goroutines 在一个go-chan上接收消息将会分发消息,而最终要的结果是复制每个消息到每一个channel(goroutine).
Instead, each topic maintains 3 primary goroutines. The first one, called router, is responsible for reading newly published messages off the incoming go-chan and storing them in a queue (memory or disk).
替代的是,每个topic维护着3个主要的goroutines。第一个被称为router,它负责用来从 incoming go-chan 读取最近发布的消息,并把消息保存到队列中(内存或硬盘)。
The second one, called messagePump, is responsible for copying and pushing messages to channels as described above.
第二个,称为messagePump,是负责复制和推送消息到如上所述的channels。
The third is responsible for DiskQueue IO and will be discussed later.
第三个是负责DiskQueue IO和将在后面讨论。
Channels are a little more complicated but share the underlying goal of exposing a single input and single output go-chan (to abstract away the fact that, internally, messages might be in memory or on disk):
Channels是一个有点复杂,但共享着 go-chan 单一输入和输出(抽象出来的事实是,在内部,消息可能会在内存或磁盘上):

Additionally, each channel maintains 2 time-ordered priority queues responsible for deferred and in-flight message timeouts (and 2 accompanying goroutines for monitoring them).
此外,每个channel的维护负责2个时间排序优先级队列,用来实现传输中(in-flight)消息超时(第2个随行goroutines用于监视它们)。
Parallelization is improved by managing a per-channel data structure, rather than relying on the Go runtime’s global timer scheduler.
并行化的提高是通过每个数据结构管理一个channel,而不是依靠Go 运行时的全局定时器调度。
Note: Internally, the Go runtime uses a single priority queue and goroutine to manage timers. This supports (but is not limited to) the entirety of the time package. It normally obviates the need for a user-land time-ordered priority queue but it’s important to keep in mind that it’s a single data structure with a single lock, potentially impacting GOMAXPROCS > 1 performance. See runtime/time.goc.
注意:在内部,Go 运行时使用一个单一优先级队列和的goroutine来管理定时器。这支持(但不局限于)的整个time package。它通常避免了需要一个用户空间的时间顺序的优先级队列,但要意识到这是一个很重要的一个有着单一锁的数据结构,有可能影响GOMAXPROCS> 1的表现。请参阅 runtime/time.goc。
####Backend / DiskQueue
One of NSQ’s design goals is to bound the number of messages kept in memory. It does this by transparently writing message overflow to disk via DiskQueue (which owns the third primary goroutine for a topic or channel).
NSQ的设计目标之一就是要限定保持在内存中的消息数。它通过 DiskQueue 透明地将溢出的消息写入到磁盘上(对于一个topic或 channel 而言,DiskQueue 拥有的第三个主要的goroutine)。
Since the memory queue is just a go-chan, it’s trivial to route messages to memory first, if possible, then fallback to disk:
由于内存队列只是一个 go-chan,把消息放到内存中显得不重要,如果可能的话,则退回到磁盘:
for msg := range c.incomingMsgChan {
select {
case c.memoryMsgChan <- msg:
default:
err := WriteMessageToBackend(&msgBuf, msg, c.backend)
if err != nil {
// ... handle errors ...
}
}
}
Taking advantage of Go’s select statement allows this functionality to be expressed in just a few lines of code: the default case above only executes if memoryMsgChan is full.
说到Go select 语句的优势在于用在短短的几行代码实现这个功能:default 语句只在memoryMsgChan已满的情况下执行。
NSQ also has the concept of ephemeral channels. Ephemeral channels discard message overflow (rather than write to disk) and disappear when they no longer have clients subscribed. This is a perfect use case for Go’s interfaces. Topics and channels have a struct member declared as a Backend interface rather than a concrete type. Normal topics and channels use a DiskQueue while ephemeral channels stub in a DummyBackendQueue, which implements a no-op Backend.
NSQ还具有的临时channel的概念。临时的channel将丢弃溢出的消息(而不是写入到磁盘),在没有客户端订阅时消失。这是一个完美的Go’s Interface 案例。topics 和 channel 有一个结构成员声明为一个 Backend interface,而不是一个具体的类型。正常的topic和channel使用DiskQueue,而临时channel stub in a DummyBackendQueue,它实现了一个no-op 的Backend。
Reducing GC Pressure 降低GC的压力
In any garbage collected environment you’re subject to the tension between throughput (doing useful work), latency (responsiveness), and resident set size (footprint).
在任何垃圾回收环境中,你可能会关注到吞吐量量(做无用功),延迟(响应),并驻留集大小(footprint)。
As of Go 1.2, the GC is mark-and-sweep (parallel), non-generational, non-compacting, stop-the-world and mostly precise . It’s mostly precise because the remainder of the work wasn’t completed in time (it’s slated for Go 1.3).
Go的1.2版本,GC采用,mark-and-sweep (parallel), non-generational, non-compacting, stop-the-world and mostly precise。这主要是因为剩余的工作未完成(它预定于Go 1.3 实现)。
The Go GC will certainly continue to improve, but the universal truth is: the less garbage you create the less time you’ll collect.
Go 的 GC一定会不断改进,但普遍的真理是:你创建的垃圾越少,收集的时间越少。
First, it’s important to understand how the GC is behaving under real workloads. To this end, nsqd publishes GC stats in statsd format (alongside other internal metrics). nsqadmin displays graphs of these metrics, giving you insight into the GC’s impact in both frequency and duration:
首先,重要的是要了解GC在真实的工作负载下是如何表现。为此,nsqd以statsd格式发布的GC统计(伴随着其他的内部指标)。nsqadmin显示这些度量的图表,让您洞察GC的影响,频率和持续时间:

In order to actually reduce garbage you need to know where it’s being generated. Once again the Go toolchain provides the answers:
为了切实减少垃圾,你需要知道它是如何生成的。再次Go toolchain 提供了答案:
- Use the testing package and go test -benchmem to benchmark hot code paths. It profiles the number of allocations per iteration (and benchmark runs can be compared with benchcmp).
使用testing package 和 go test benchmem来 benchmark 热点代码路径。它分析每个迭代分配的内存数量(和benchmark 运行可以用 benchcmp 进行比较)。
- Build using go build -gcflags -m, which outputs the result of escape analysis.
编译时使用 go build -gcflags -m , 会输出逃逸分析的结果。
With that in mind, the following optimizations proved useful for nsqd:
考虑到这一点,下面的优化证明对nsqd是有用的:
- Avoid []byte to string conversions.
避免[]byte 到 string 的转换
- Re-use buffers or objects (and someday possibly sync.Pool aka issue 4720).
buffers 或 object 的重新利用(并且某一天可能面临 ync.Pool 又名 issue 4720)
- Pre-allocate slices (specify capacity in make) and always know the number and size of items over the wire.
预先分配 slices(在make时指定容量)并且总是知道其中承载元素的数量和大小
- Apply sane limits to various configurable dials (such as message size).
对各种配置项目使用一些明智的限制(例如消息大小)
- Avoid boxing (use of interface{}) or unnecessary wrapper types (like a struct for a “multiple value” go-chan).
避免装箱(使用 interface{})或一些不必要的包装类型(例如一个 多值的”go-chan” 结构体)
- Avoid the use of defer in hot code paths (it allocates).
避免在热点代码路径使用defer(它也消耗内存)
TCP Protocol
The NSQ TCP protocol is a shining example of a section where these GC optimization concepts are utilized to great effect.
NSQ的TCP协议是一个这些GC优化概念发挥了很大作用的的辉榜样。
The protocol is structured with length prefixed frames, making it straightforward and performant to encode and decode:
该协议用含有长度前缀的帧构造,使其可以直接高效的编码和解码:
[x][x][x][x][x][x][x][x][x][x][x][x]...
| (int32) || (int32) || (binary)
| 4-byte || 4-byte || N-byte
------------------------------------...
size frame ID data
Since the exact type and size of a frame’s components are known ahead of time, we can avoid the encoding/binary package’s convenience Read() and Write() wrappers (and their extraneous interface lookups and conversions) and instead call the appropriate binary.BigEndian methods directly.
由于提前知道了帧部件的确切类型与大小,我们避免了 encodgin/binary 便利 Read() 和 Write() 包装(以及它们外部interface 的查询与转换),而是直接调用相应的 binary.BigEndian 方法。
To reduce socket IO syscalls, client net.Conn are wrapped with bufio.Reader and bufio.Writer. The Reader exposes ReadSlice(), which reuses its internal buffer. This nearly eliminates allocations while reading off the socket, greatly reducing GC pressure. This is possible because the data associated with most commands does not escape (in the edge cases where this is not true, the data is explicitly copied).
为了减少 socket 的IO系统调用,客户端 net.Conn 都用 bufio.Reader和bufio.Writer 包装。Reader 暴露了 ReadSlice() ,它会重复使用其内部缓冲区。这几乎消除了从socket 读出数据的内存分配,大大降低GC的压力。这可能是因为与大多数命令关联的数据does not escape(在边缘情况下,这是不正确的,数据是显示复制的)。
At an even lower level, a MessageID is declared as [16]byte to be able to use it as a map key (slices cannot be used as map keys). However, since data read from the socket is stored as []byte, rather than produce garbage by allocating string keys, and to avoid a copy from the slice to the backing array of the MessageID, the unsafe package is used to cast the slice directly to a MessageID:
在一个更低的水平,提供一个 MessageID 被声明为[16]byte,以便能够把它作为一个map key(slice不能被用作map key)。然而,由于从socket读取数据存储为[]byte,而不是通过分配字符串键产生垃圾,并避免从slice的副本拷贝的数组形式的MessageID, unsafe package是用来直接把 slice 转换成一个MessageID:
id := *(*nsq.MessageID)(unsafe.Pointer(&msgID))
Note: This is a hack. It wouldn’t be necessary if this was optimized by the compiler and Issue 3512 is open to potentially resolve this. It’s also worth reading through issue 5376, which talks about the possibility of a “const like” byte type that could be used interchangeably where string is accepted, without allocating and copying.
注: 这是一个hack。它将不是必要的,如果编译器优化 和 Issue 3512 解决这个问题。另外值得一读通过issue 5376,其中谈到的“const like” byte 类型 与 string 类型可以互换使用,而不需要分配和复制。
Similarly, the Go standard library only provides numeric conversion methods on a string. In order to avoid string allocations, nsqd uses a custom base 10 conversion method that operates directly on a []byte.
同样,Go 标准库只提供了一个数字转换成string的方法。为了避免string分配,nsqd使用一个自定义的10进制转换方法在[]byte直接操作。
These may seem like micro-optimizations but the TCP protocol contains some of the hottest code paths. In aggregate, at the rate of tens of thousands of messages per second, they have a significant impact on the number of allocations and overhead:
这些看似微观优化,但却包含了TCP协议中一些最热门的代码路径。总体而言,每秒上万消息的速度,对分配和开销的数目显著影响:
benchmark old ns/op new ns/op delta
BenchmarkProtocolV2Data 3575 1963 -45.09%
benchmark old ns/op new ns/op delta
BenchmarkProtocolV2Sub256 57964 14568 -74.87%
BenchmarkProtocolV2Sub512 58212 16193 -72.18%
BenchmarkProtocolV2Sub1k 58549 19490 -66.71%
BenchmarkProtocolV2Sub2k 63430 27840 -56.11%
benchmark old allocs new allocs delta
BenchmarkProtocolV2Sub256 56 39 -30.36%
BenchmarkProtocolV2Sub512 56 39 -30.36%
BenchmarkProtocolV2Sub1k 56 39 -30.36%
BenchmarkProtocolV2Sub2k 58 42 -27.59%
HTTP
NSQ’s HTTP API is built on top of Go’s net/http package. Because it’s just HTTP, it can be leveraged in almost any modern programming environment without special client libraries.
NSQ的HTTP API是建立在Go的 net/http 包之上。因为它只是 HTTP,它可以利用没有特殊的客户端库的几乎所有现代编程环境。
Its simplicity belies its power, as one of the most interesting aspects of Go’s HTTP tool-chest is the wide range of debugging capabilities it supports. The net/http/pprof package integrates directly with the native HTTP server, exposing endpoints to retrieve CPU, heap, goroutine, and OS thread profiles. These can be targeted directly from the go tool:
它的简单性掩盖了它的能力,作为Go的HTTP tool-chest最有趣的方面之一是广泛的调试功能支持。该 net/http/pprof 包直接集成了原生的HTTP服务器,暴露获取CPU,堆,goroutine和操作系统线程性能的endpoints。这些可以直接从 go tool 找到:
$ go tool pprof http://127.0.0.1:4151/debug/pprof/profile
This is a tremendously valuable for debugging and profiling a running process!
这对调试和分析一个运行的进程非常有价值!
In addition, a /stats endpoint returns a slew of metrics in either JSON or pretty-printed text, making it easy for an administrator to introspect from the command line in realtime:
此外,/stats endpoint 返回的指标摆在任何JSON或良好格式的文本,很容易使管理员能够实时从命令行监控:
$ watch -n 0.5 'curl -s http://127.0.0.1:4151/stats | grep -v connected'
This produces continuous output like:
这产生的连续输出如下:
[page_views ] depth: 0 be-depth: 0 msgs: 105525994 e2e%: 6.6s, 6.2s, 6.2s
[page_view_counter ] depth: 0 be-depth: 0 inflt: 432 def: 0 re-q: 34684 timeout: 34038 msgs: 105525994 e2e%: 5.1s, 5.1s, 4.6s
[realtime_score ] depth: 1828 be-depth: 0 inflt: 1368 def: 0 re-q: 25188 timeout: 11336 msgs: 105525994 e2e%: 9.0s, 9.0s, 7.8s
[variants_writer ] depth: 0 be-depth: 0 inflt: 592 def: 0 re-q: 37068 timeout: 37068 msgs: 105525994 e2e%: 8.2s, 8.2s, 8.2s
[poll_requests ] depth: 0 be-depth: 0 msgs: 11485060 e2e%: 167.5ms, 167.5ms, 138.1ms
[social_data_collector ] depth: 0 be-depth: 0 inflt: 2 def: 3 re-q: 7568 timeout: 402 msgs: 11485060 e2e%: 186.6ms, 186.6ms, 138.1ms
[social_data ] depth: 0 be-depth: 0 msgs: 60145188 e2e%: 199.0s, 199.0s, 199.0s
[events_writer ] depth: 0 be-depth: 0 inflt: 226 def: 0 re-q: 32584 timeout: 30542 msgs: 60145188 e2e%: 6.7s, 6.7s, 6.7s
[social_delta_counter ] depth: 17328 be-depth: 7327 inflt: 179 def: 1 re-q: 155843 timeout: 11514 msgs: 60145188 e2e%: 234.1s, 234.1s, 231.8s
[time_on_site_ticks] depth: 0 be-depth: 0 msgs: 35717814 e2e%: 0.0ns, 0.0ns, 0.0ns
[tail821042#ephemeral ] depth: 0 be-depth: 0 inflt: 0 def: 0 re-q: 0 timeout: 0 msgs: 33909699 e2e%: 0.0ns, 0.0ns, 0.0ns
Finally, Go 1.2 brought measurable HTTP performance gains. It’s always nice when recompiling against the latest version of Go provides a free performance boost!
最后,Go 1.2带来可观的HTTP性能提升。与Go的最新版本重新编译时,它总是很高兴为您提供免费的性能提升!
#### Dependencies 依赖
Coming from other ecosystems, Go’s philosophy (or lack thereof) on managing dependencies takes a little time to get used to.
对于其它生态系统,Go 依赖关系管理(或缺乏)的哲学需要一点时间去适应。
NSQ evolved from being a single giant repo, with relative imports and little to no separation between internal packages, to fully embracing the recommended best practices with respect to structure and dependency management.
NSQ从一个单一的巨大仓库衍化而来的,包含相关的imports 和 小到未分离的内部 packages,完全遵守构建和依赖管理的最佳实践。
There are two main schools of thought:
有两大流派的思想:
- Vendoring: copy dependencies at the correct revision into your application’s repo and modify your import paths to reference the local copy.
Vendoring:拷贝正确版本的依赖到你的应用程序的仓库,并修改您的import 路径来引用本地副本。
- Virtual Env: list the revisions of dependencies you require and at build time, produce a pristine GOPATH environment containing those pinned dependencies.
Virtual Env:列出你在构建时所需要的依赖版本,产生一种原生的GOPATH环境变量包含这些固定依赖。
Note: This really only applies to binary packages as it doesn’t make sense for an importable package to make intermediate decisions as to which version of a dependency to use.
注:这确实只适用于二进制包,因为它没有任何意义的一个导入的包,使中间的决定,如一种依赖使用的版本。
NSQ uses godep to provide support for (2) above.
NSQ 使用 godep 提供如上述2中的支持。
It works by recording your dependencies in a Godeps file, which it later uses to construct a GOPATH environment. To build, it wraps and executes the standard Go toolchain inside that environment. The Godeps file is just JSON and can be edited by hand.
它的工作原理是在Godeps文件记录你的依赖,方便日后构建GOPATH环境。为了编译,它在环境里包装并执行的标准Go toolchain。该Godeps文件仅仅是JSON格式,可以进行手工编辑。
It even supports go get like semantics. For example, to produce a reliable build of NSQ:
它甚至还支持像 go get 的语义。例如,用来产生可靠的NSQ构建:
$ godep get github.com/bitly/nsq/...
Testing
Go provides solid built-in support for writing tests and benchmarks and, because Go makes it so easy to model concurrent operations, it’s trivial to stand up a full-fledged instance of nsqd inside your test environment.
Go 提供了编写测试和基准测试的内建支持,这使用 Go 很容易并发操作进行建模,这是微不足道的站起来的一个完整的实例nsqd您的测试环境中。
However, there was one aspect of the initial implementation that became problematic for testing: global state. The most obvious offender was the use of a global variable that held the reference to the instance of nsqd at runtime, i.e. var nsqd *NSQd.
然而,最初实现有可能变成测试问题的一个方面:全局状态。最明显的offender 是运行时使用该持有nsqd 的引用实例的全局变量,例如 包含配置元数据 和 到parent nsqd的引用。
Certain tests would inadvertently mask this global variable in their local scope by using short-form variable assignment, i.e. nsqd := NewNSQd(…). This meant that the global reference did not point to the instance that was currently running, breaking tests.
某些测试会使用短形式的变量赋值,无意中在局部范围掩盖这个全局变量,即nsqd:= NewNSQd(…) 。这意味着,全局引用没有指向了当前正在运行的实例,破坏了测试实例。
To resolve this, a Context struct is passed around that contains configuration metadata and a reference to the parent nsqd. All references to global state were replaced with this local Context, allowing children (topics, channels, protocol handlers, etc.) to safely access this data and making it more reliable to test.
要解决这个问题,一个包含配置元数据 和 到parent nsqd的引用 上下文结构被传来传去。到全局状态的所有引用都替换为本地的语境,允许 children(topics,channels,协议处理程序等)来安全地访问这些数据,使之更可靠的测试。
Robustness
A system that isn’t robust in the face of changing network conditions or unexpected events is a system that will not perform well in a distributed production environment.
一个面对不断变化的网络条件或突发事件不健壮的系统,不会是一个在分布式生产环境中表现良好的系统。
NSQ is designed and implemented in a way that allows the system to tolerate failure and behave in a consistent, predictable, and unsurprising way.
NSQ设计和的方式是 使系统能够容忍故障而表现出一致的,可预测的和令人吃惊的方式来实现。
The overarching philosophy is to fail fast, treat errors as fatal, and provide a means to debug any issues that do occur.
总体理念是快速失败, treat errors as fatal,并提供了一种方式来调试发生的任何问题。
But, in order to react you need to be able to detect exceptional conditions
但是,为了应对,你需要能够检测异常情况
Heartbeats and Timeouts
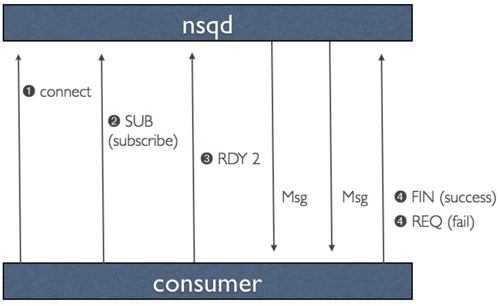
The NSQ TCP protocol is push oriented. After connection, handshake, and subscription the consumer is placed in a RDY state of 0. When the consumer is ready to receive messages it updates that RDY state to the number of messages it is willing to accept. NSQ client libraries continually manage this behind the scenes, resulting in a flow-controlled stream of messages.
NSQ 的TCP协议是面向push的。在建立连接,握手,和订阅后,消费者被放置在一个为0的RDY状态。当消费者准备好接收消息,它更新的RDY状态到准备接收消息的数量。NSQ客户端库不断在幕后管理,消息控制流的结果。
Periodically, nsqd will send a heartbeat over the connection. The client can configure the interval between heartbeats but nsqd expects a response before it sends the next one.
每隔一段时间,nsqd将发送一个心跳线连接。客户端可以配置心跳之间的间隔,但nsqd会期待一个回应在它发送下一个心掉之前。
The combination of application level heartbeats and RDY state avoids head-of-line blocking, which can otherwise render heartbeats useless (i.e. if a consumer is behind in processing message flow the OS’s receive buffer will fill up, blocking heartbeats).
组合应用级别的心跳和RDY状态,避免头阻塞现象,也可能使心跳无用(即,如果消费者是在后面的处理消息流的接收缓冲区中的操作系统将被填满,堵心跳)。
To guarantee progress, all network IO is bound with deadlines relative to the configured heartbeat interval. This means that you can literally unplug the network connection between nsqd and a consumer and it will detect and properly handle the error.
为了保证进度,所有的网络IO时间上限势必与配置的心跳间隔相关联。这意味着,你可以从字面上拔掉之间的网络连接nsqd和消费者,它会检测并正确处理错误。
When a fatal error is detected the client connection is forcibly closed. In-flight messages are timed out and re-queued for delivery to another consumer. Finally, the error is logged and various internal metrics are incremented.
当检测到一个致命错误,客户端连接被强制关闭。在传输中的消息会超时而重新排队等待传递到另一个消费者。最后,错误会被记录并累计到各种内部指标。
Managing Goroutines 管理 Goroutines
It’s surprisingly easy to start goroutines. Unfortunately, it isn’t quite as easy to orchestrate their cleanup. Avoiding deadlocks is also challenging. Most often this boils down to an ordering problem, where a goroutine receiving on a go-chan exits before the upstream goroutines sending on it.
非常容易启动 goroutine。不幸的是,不是很容易以协调他们的清理工作。避免死锁也极具挑战性。大多数情况下这可以归结为一个顺序的问题,在上游goroutine 发送消息到 go-chan 之前,另一个goroutine 从 go-chan 上接收消息。
Why care at all though? It’s simple, an orphaned goroutine is a memory leak. Memory leaks in long running daemons are bad, especially when the expectation is that your process will be stable when all else fails.
为什么要关心这些?这很显然,孤立的goroutine是内存泄漏。内存泄露在长期运行的守护进程中是相当糟糕的,尤其当期望的是你的进程能够稳定运行,但其它都失败了。
To further complicate things, a typical nsqd process has many goroutines involved in message delivery. Internally, message “ownership” changes often. To be able to shutdown cleanly, it’s incredibly important to account for all intraprocess messages.
更复杂的是,一个典型的nsqd进程中有许多参与消息传递 goroutines。在内部,消息的“所有权”频繁变化。为了能够完全关闭,统计全部进程内的消息是非常重要的。
Although there aren’t any magic bullets, the following techniques make it a little easier to manage
虽然目前还没有任何灵丹妙药,下列技术使它变得更轻松管理
WaitGroups
The sync package provides sync.WaitGroup, which can be used to perform accounting of how many goroutines are live (and provide a means to wait on their exit).
sync 包提供了 sync.WaitGroup, 可以被用来累计多少个 goroutine 是活跃的(并且意味着一直等待直到它们退出)。
To reduce the typical boilerplate, nsqd uses this wrapper:
为了减少经典样板,nsqd 使用以下装饰器:
type WaitGroupWrapper struct {
sync.WaitGroup
}
func (w *WaitGroupWrapper) Wrap(cb func()) {
w.Add(1)
go func() {
cb()
w.Done()
}()
}
// can be used as follows:
wg := WaitGroupWrapper{}
wg.Wrap(func() { n.idPump() })
...
wg.Wait()
Exit Signaling 退出信号
The easiest way to trigger an event in multiple child goroutines is to provide a single go-chan that you close when ready. All pending receives on that go-chan will activate, rather than having to send a separate signal to each goroutine.
有一个简单的方式在多个child goroutine 中触发一个事件是 提供一个go-chane, 当你准备好时关闭它。所有在那个 go-chan 上挂起的go-chan 都将会被激活,而不是向每个goroutine中发送一个单独的信号。
func work() {
exitChan := make(chan int)
go task1(exitChan)
go task2(exitChan)
time.Sleep(5 * time.Second)
close(exitChan)
}
func task1(exitChan chan int) {
<-exitChan
log.Printf("task1 exiting")
}
func task2(exitChan chan int) {
<-exitChan
log.Printf("task2 exiting")
}
Synchronizing Exit 退出时的同步
It was quite difficult to implement a reliable, deadlock free, exit path that accounted for all in-flight messages. A few tips:
实现一个可靠的,无死锁的,所有传递中的消息的退出路径 是相当困难的。一些提示:
Ideally the goroutine responsible for sending on a go-chan should also be responsible for closing it.
理想的情况是负责发送到go-chan的goroutine中也应负责关闭它。
If messages cannot be lost, ensure that pertinent go-chans are emptied (especially unbuffered ones!) to guarantee senders can make progress.
如果message不能丢失,确保相关的 go-chan 被清空(尤其是无缓冲的!),以保证发送者可以取得进展。
Alternatively, if a message is no longer relevant, sends on a single go-chan should be converted to a select with the addition of an exit signal (as discussed above) to guarantee progress.
另外,如果消息是不重要的,发送给一个单一的 go-chan 应转换为一个 select 附加一个退出信号(如上所述),以保证取得进展。
The general order should be:
一般的顺序应该是:
- Stop accepting new connections (close listeners)
停止接受新的连接(close listeners)
- Signal exit to child goroutines (see above)
发送退出信号给child goroutines(如上文)
- Wait on WaitGroup for goroutine exit (see above)
在 WaitGroup 等待 goroutine 退出(如上文)
- Recover buffered data
恢复缓冲数据
- Flush anything left to disk
刷新所有东西到硬盘
Logging 日志
Finally, the most important tool at your disposal is to log the entrance and exit of your goroutines!. It makes it infinitely easier to identify the culprit in the case of deadlocks or leaks.
最后,日志是您所获得的记录goroutine进入和退出的重要工具!。这使得它相当容易识别死锁或泄漏的情况的罪魁祸首。
nsqd log lines include information to correlate goroutines with their siblings (and parent), such as the client’s remote address or the topic/channel name.
nsqd日志行包括goroutine 与他们的siblings(and parent)的信息,如客户端的远程地址或 topic/channel name。
The logs are verbose, but not verbose to the point where the log is overwhelming. There’s a fine line, but nsqd leans towards the side of having more information in the logs when a fault occurs rather than trying to reduce chattiness at the expense of usefulness.
该日志是冗长的,但不是冗长的地步日志是压倒性的。有一条细线,但nsqd 倾向于发生故障时在日志中提供更多的信息,而不是试图减少繁琐的有效性为代价。