NSQ Design设计
NSQ is a successor to simplequeue (part of simplehttp[https://github.com/bitly/simplehttp]) and as such is designed to (in no particular order):
NSQ是继承于 simplequeue(部分的 simplehttp),因此被设计为(排名不分先后):
- provide easy topology solutions that enable high-availability and eliminate SPOFs
提供更简单的拓扑方案,达到高可性和消除单点故障 - address the need for stronger message delivery guarantees
满足更强的消息可靠传递的保证 - bound the memory footprint of a single process (by persisting some messages to disk)
限制单个进程的内存占用(通过持久化一些消息到硬盘上) - greatly simplify configuration requirements for producers and consumers
极大简化了生产者和消费者的配置要求 - provide a straightforward upgrade path
提供了一个简单的升级路径 - improve efficiency
提升效率
Simplifying Configuration and Administration 简化配置和管理
A single nsqd instance is designed to handle multiple streams of data at once. Streams are called “topics” and a topic has 1 or more “channels”. Each channel receives a copy of all the messages for a topic. In practice, a channel maps to a downstream service consuming a topic.
单个 nsqd 实例被设计成可以同时处理多个数据流。流被称为“topics”和 topics有1个或多个“channel”。每个channel 都接收到一个topic 中所有消息的拷贝。在实践中,一个channel映射到下行服务消费一个topic。
Topics and channels are not configured a priori. Topics are created on first use by publishing to the named topic or by subscribing to a channel on the named topic. Channels are created on first use by subscribing to the named channel.
topic 和 channel 都没有预先配置。topic 由第一次发布消息到命名的topic 或第一次通过订阅一个命名topic来创建。channel 被第一次订阅到指定的channel创建。
Topics and channels all buffer data independently of each other, preventing a slow consumer from causing a backlog for other channels (the same applies at the topic level).
topic和channel的所有缓冲的数据相互独立,防止缓慢消费者造成对其他channel的积压(同样适用于topic级别)。
A channel can, and generally does, have multiple clients connected. Assuming all connected clients are in a state where they are ready to receive messages, each message will be delivered to a random client. For example:
一个channel就可以了,一般会有多个客户端连接。假设所有已连接的客户端处于准备接收消息的状态,每个消息将被传递到一个随机的客户端。例如:

To summarize, messages are multicast from topic -> channel (every channel receives a copy of all messages for that topic) but evenly distributed from channel -> consumers (each consumer receives a portion of the messages for that channel).
总之,消息从topic->channel 是多播的(每个channel接收的所有该topic消息的副本),即使均匀分布在 topic->sonsumers 之间(每个消费者收到该channel的消息的一部分)。
NSQ also includes a helper application, nsqlookupd, which provides a directory service where consumers can lookup the addresses of nsqd instances that provide the topics they are interested in subscribing to. In terms of configuration, this decouples the consumers from the producers (they both individually only need to know where to contact common instances of nsqlookupd, never each other), reducing complexity and maintenance.
NSQ还包括一个辅助应用程序,nsqlookupd,它提供了一个目录服务,消费者可以查找到提供他们感兴趣订阅topic的 nsqd 地址 。在配置方面,把消费者与生产者解耦开(它们都分别只需要知道哪里去连接nsqlookupd的共同实例,而不是对方),降低复杂性和维护。
At a lower level each nsqd has a long-lived TCP connection to nsqlookupd over which it periodically pushes its state. This data is used to inform which nsqd addresses nsqlookupd will give to consumers. For consumers, an HTTP /lookup endpoint is exposed for polling.
在更底的层面,每个nsqd有一个与 nsqlookupd 的长期TCP连接,定期推动其状态。这个数据被nsqlookupd用于给消费者通知nsqd地址。对于消费者来说,一个暴露的 HTTP /lookup 接口用于轮询。
To introduce a new distinct consumer of a topic, simply start up an NSQ client configured with the addresses of your nsqlookupd instances. There are no configuration changes needed to add either new consumers or new publishers, greatly reducing overhead and complexity.
为topic 引入一个新的消费者,只需启动一个配置了 nsqlookup实例地址的NSQ 客户端。无需为添加任何新的消费者或生产者更改配置,大大降低了开销和复杂性。
NOTE: in future versions, the heuristic nsqlookupd uses to return addresses could be based on depth, number of connected clients, or other “intelligent” strategies. The current implementation is simply all. Ultimately, the goal is to ensure that all producers are being read from such that depth stays near zero.
注:在将来的版本中,启发式nsqlookupd可以基于深度,已连接的客户端数量,或其他“智能”策略来返回地址。当前的实现是简单的返回所有地址。最终的目标是要确保所有深度接近零的生产者被读取。
It is important to note that the nsqd and nsqlookupd daemons are designed to operate independently, without communication or coordination between siblings.
值得注意的是,重要的是nsqd和nsqlookupd守护进程被设计成独立运行,没有相互之间的沟通或协调。
We also think that it’s really important to have a way to view, introspect, and manage the cluster in aggregate. We built nsqadmin to do this. It provides a web UI to browse the hierarchy of topics/channels/consumers and inspect depth and other key statistics for each layer. Additionally it supports a few administrative commands such as removing and emptying a channel (which is a useful tool when messages in a channel can be safely thrown away in order to bring depth back to 0).
我们还认为重要的是有一个方式来聚合 查看,监测,并管理集群。我们建立nsqadmin做到这一点。它提供了一个Web UI来浏览topic/channels/consumers 和深度检查等每一层的关键统计数据。此外,它还支持几个管理命令例如 移除channel 和 清空channel(这是一个有用的工具,当在一个channel中的信息可以被安全地扔掉,以使深度返回到0)。
Straightforward Upgrade Path 简单的升级路径
This was one of our highest priorities. Our production systems handle a large volume of traffic, all built upon our existing messaging tools, so we needed a way to slowly and methodically upgrade specific parts of our infrastructure with little to no impact.
这是我们的高优先级之一。我们的生产系统处理大量的流量,都建立在我们现有的消息工具上,所以我们需要一种方法来慢慢地,有条不紊地升级我们特定部分的基础设施,而不产生任何影响。
First, on the message producer side we built nsqd to match simplequeue. Specifically, nsqd exposes an HTTP /put endpoint, just like simplequeue, to POST binary data (with the one caveat that the endpoint takes an additional query parameter specifying the “topic”). Services that wanted to switch to start publishing to nsqd only have to make minor code changes.
首先,在消息生产者方面,我们建立nsqd匹配simplequeue。具体来说,nsqd暴露了一个 HTTP /PUT 端点,就像simplequeue,上传二进制数据(需要注意的一点是 endpoint 需要一个额外的查询参数来指定”topic”)。想切换到发布消息到nsqd的服务只需要很少的代码变更。
Second, we built libraries in both Python and Go that matched the functionality and idioms we had been accustomed to in our existing libraries. This eased the transition on the message consumer side by limiting the code changes to bootstrapping. All business logic remained the same.
第二,我们建立了兼容已有库功能和语义的Python和Go库。这使得消息的消费者通过很少的代码改变来使用。所有的业务逻辑保持不变。
Finally, we built utilities to glue old and new components together. These are all available in the examples directory in the repository:
最后,我们建立工具连接起新旧组件。这些都在仓库的示例目录中:
1. nsq_pubsub - expose a pubsub like HTTP interface to topics in an NSQ cluster
nsq_pubsub -在NSQ集群中以HTTP接口的形式暴露的一个pubsub
2. nsq_to_file - durably write all messages for a given topic to a file
nsq_to_file -将一个给定topic的所有消息持久化到文件
3. nsq_to_http - perform HTTP requests for all messages in a topic to (multiple) endpoints
nsq_to_http -对一个topic的所有消息的执行HTTP请求到(多个)endpoints
Eliminating SPOFs
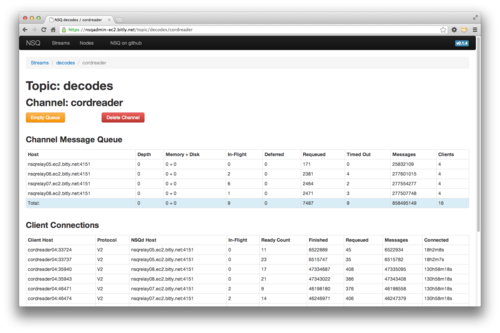
NSQ is designed to be used in a distributed fashion. nsqd clients are connected (over TCP) to all instances providing the specified topic. There are no middle-men, no message brokers, and no SPOFs:
NSQ被设计以分布的方式被使用。nsqd客户端(通过TCP)连接到指定topic的所有生产者实例。没有中间人,没有消息代理,也没有单点故障:
This topology eliminates the need to chain single, aggregated, feeds. Instead you consume directly from all producers. Technically, it doesn’t matter which client connects to which NSQ, as long as there are enough clients connected to all producers to satisfy the volume of messages, you’re guaranteed that all will eventually be processed.
这种拓扑结构消除单链,聚合,反馈。相反,你的消费者直接访问所有所有生产者。从技术上讲,哪个客户端连接到哪个NSQ产东重要,只要有足够的消费者连接到所有生产者,以满足大量的消息,你能被保证:所有最终将被处理。
For nsqlookupd, high availability is achieved by running multiple instances. They don’t communicate directly to each other and data is considered eventually consistent. Consumers poll all of their configured nsqlookupd instances and union the responses. Stale, inaccessible, or otherwise faulty nodes don’t grind the system to a halt.
对于nsqlookupd,高可用性是通过运行多个实例来实现。他们不直接相互通信和数据被认为是最终一致。消费者轮询所有的配置的nsqlookupd实例和合并response。失败的,无法访问的,或以其他方式故障的节点不会让系统陷于停顿。
Message Delivery Guarantees 消息传递担保
NSQ guarantees that a message will be delivered at least once, though duplicate messages are possible. Consumers should expect this and de-dupe or perform idempotent operations.
NSQ保证消息将交付至少一次,虽然重复的消息是可能的。消费者应该关注到这一点,删除重复数据或执行幂等操作。
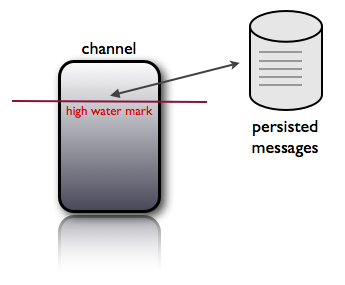
This guarantee is enforced as part of the protocol and works as follows (assume the client has successfully connected and subscribed to a topic):
这个担保是作为协议和工作流的一部分,工作原理如下(假设客户端成功连接并订阅一个topic):
- client indicates they are ready to receive messages
客户表示他们已经准备好接收消息 - NSQ sends a message and temporarily stores the data locally (in the event of re-queue or timeout)
NSQ发送一条消息,并暂时将数据存储在本地(在re-queue或timeout) - client replies FIN (finish) or REQ (re-queue) indicating success or failure respectively. If client does not reply NSQ will timeout after a configurable duration and automatically re-queue the message
客户端回复FIN(结束)或REQ(重新排队)分别指示成功或失败。如果客户端没有回复,NSQ会在设定的时间超时,自动重新排队消息
This ensures that the only edge case that would result in message loss is an unclean shutdown of an nsqd process. In that case, any messages that were in memory (or any buffered writes not flushed to disk) would be lost.
这确保了消息丢失唯一可能的情况是不正常结nsqd进程。在这种情况下,这是在内存中的任何信息(或任何缓冲未刷新到磁盘)都将丢失。
If preventing message loss is of the utmost importance, even this edge case can be mitigated. One solution is to stand up redundant nsqd pairs (on separate hosts) that receive copies of the same portion of messages. Because you’ve written your consumers to be idempotent, doing double-time on these messages has no downstream impact and allows the system to endure any single node failure without losing messages.
如何防止消息丢失是最重要的,即使是这个意外情况可以得到缓解。一种解决方案是构成冗余nsqd对(在不同的主机上)接收消息的相同部分的副本。因为你实现的消费者是幂等的,以两倍时间处理这些消息不会对下游造成影响,并使得系统能够承受任何单一节点故障而不会丢失信息。
The takeaway is that NSQ provides the building blocks to support a variety of production use cases and configurable degrees of durability.
附加的是 NSQ 提供构建基础以支持多种生产用例和持久化的可配置性。
Bounded Memory Footprint 限定内存占用
nsqd provides a configuration option –mem-queue-size that will determine the number of messages that are kept in memory for a given queue. If the depth of a queue exceeds this threshold messages are transparently written to disk. This bounds the memory footprint of a given nsqd process to mem-queue-size #_of_channels_and_topics:
nsqd提供一个 –mem-queue-size 配置选项,这将决定一个队列保存在内存中的消息数量。如果队列深度超过此阈值,消息将透明地写入磁盘。nsqd 进程的内存占用被限定于 mem-queue-size #_of_channels_and_topics:
Also, an astute observer might have identified that this is a convenient way to gain an even higher guarantee of delivery by setting this value to something low (like 1 or even 0). The disk-backed queue is designed to survive unclean restarts (although messages might be delivered twice).
此外,一个精明的观察者可能会发现,这是一个方便的方式来获得更高的传递保证:把这个值设置的比较低(如1或甚至是0)。磁盘支持的队列被设计为在不重启的情况下存在(虽然消息可能被传递两次)。
Also, related to message delivery guarantees, clean shutdowns (by sending a nsqd process the TERM signal) safely persist the messages currently in memory, in-flight, deferred, and in various internal buffers.
此外,涉及到信息传递保证,干净关机(通过给nsqd进程发送TERM信号)坚持安全地把消息保存在内存中,传输中,延迟,以及内部的各种缓冲区。
Note, a channel whose name ends in the string #ephemeral will not be buffered to disk and will instead drop messages after passing the mem-queue-size. This enables consumers which do not need message guarantees to subscribe to a channel. These ephemeral channels will also not persist after its last client disconnects.
请注意,一个以 #ephemeral 结束的 channel 名称不会在超过 mem-queue-size之后刷新到硬盘。这使得消费者并不需要订阅频道的消息担保。这些临时channel 将在最后一个客户端断开连接后消失。
Efficiency 效率
NSQ was designed to communicate over a “memcached-like” command protocol with simple size-prefixed responses. All message data is kept in the core including metadata like number of attempts, timestamps, etc. This eliminates the copying of data back and forth from server to client, an inherent property of the previous toolchain when re-queueing a message. This also simplifies clients as they no longer need to be responsible for maintaining message state.
NSQ被设计成一个使用简单 size-prefixed 为前缀的,与“memcached-like”类似的命令协议。所有的消息数据被保持在核心中,包括像尝试次数、时间截等元数据类。这消除了数据从服务器到客户端来回拷贝,当重新排队消息时先前工具链的固有属性。这也简化了客户端,因为他们不再需要负责维护消息的状态。
Also, by reducing configuration complexity, setup and development time is greatly reduced (especially in cases where there are >1 consumers of a topic).
此外,通过降低配置的复杂性,安装和开发的时间大大缩短(尤其是在有超过 > 1 消费者的topic)。
For the data protocol, we made a key design decision that maximizes performance and throughput by pushing data to the client instead of waiting for it to pull. This concept, which we call RDY state, is essentially a form of client-side flow control.
对于数据的协议,我们做了一个重要的设计决策,通过推送数据到客户端最大限度地提高性能和吞吐量的,而不是等待客户端拉数据。这个概念,我们称之为RDY状态,基本上是客户端流量控制的一种形式。
When a client connects to nsqd and subscribes to a channel it is placed in a RDY state of 0. This means that no messages will be sent to the client. When a client is ready to receive messages it sends a command that updates its RDY state to some # it is prepared to handle, say 100. Without any additional commands, 100 messages will be pushed to the client as they are available (each time decrementing the server-side RDY count for that client).
当客户端连接到nsqd和并订阅到一个channel时,它被放置在一个RDY为0状态。这意味着,还没有信息被发送到客户端。当客户端已准备好接收消息发送,更新它的命令RDY状态到它准备处理的数量,比如100。无需任何额外的指令,当100条消息可用时,将被传递到客户端(服务器端为那个客户端每次递减RDY计数)。
Client libraries are designed to send a command to update RDY count when it reaches ~25% of the configurable max-in-flight setting (and properly account for connections to multiple nsqd instances, dividing appropriately).
客户端库的被设计成在RDY count 达到配置 max-in-flight 的25% 发送一个命令来更新RDY 计数(并适当考虑连接到多个nsqd情况下,适当地分配)。
This is a significant performance knob as some downstream systems are able to more-easily batch process messages and benefit greatly from a higher max-in-flight.
这是一个重要的性能控制,使一些下游系统能够更轻松地批量处理信息,并从更高的 max-in-flight 中受益。
Notably, because it is both buffered and push based with the ability to satisfy the need for independent copies of streams (channels), we’ve produced a daemon that behaves like simplequeue and pubsub combined . This is powerful in terms of simplifying the topology of our systems where we would have traditionally maintained the older toolchain discussed above.
值得注意的是,因为它既是基于缓冲和推来满足需要(channel)流的独立副本的能力,我们已经提供了 行为像simplequeue和 pubsub 相结合的守护进程。这是简化我们的系统拓扑结构的强大工具,如上述讨论那样我们会维护传统的toolchain。
Go
We made a strategic decision early on to build the NSQ core in Go. We recently blogged about our use of Go at bitly and alluded to this very project - it might be helpful to browse through that post to get an understanding of our thinking with respect to the language.
我们早早做了一个战略决策,利用Go来建立NSQ的核心。我们最近的博客上讲述我们在bitly如何使用Go,并提到这个适合的项目-通过浏览那篇文章可能对理解我们如何重视这么语言有所帮助。
Regarding NSQ, Go channels (not to be confused with NSQ channels) and the language’s built in concurrency features are a perfect fit for the internal workings of nsqd. We leverage buffered channels to manage our in memory message queues and seamlessly write overflow to disk.
关于NSQ,Go channels(不要与NSQ channel混淆),并且内置并发性功能的语言的非常适合于的nsqd的内部工作。我们充分利用缓冲的channel 来管理我们在内存中的消息队列和无缝r把溢出消息放到硬盘。
The standard library makes it easy to write the networking layer and client code. The built in memory and cpu profiling hooks highlight opportunities for optimization and require very little effort to integrate. We also found it really easy to test components in isolation, mock types using interfaces, and iteratively build functionality.
标准库使得很容易地编写网络层和客户端代码。只需要付出很少的努力,来整合内置的内存和CPU剖析进行优化。我们还发现它易于单独测试组件,模拟类型接口,以迭代方式构建功能。