我们团队正在开发一个相册类产品,希望打造一个基于存储为中心的相册服务。
产品的基本架构如下:
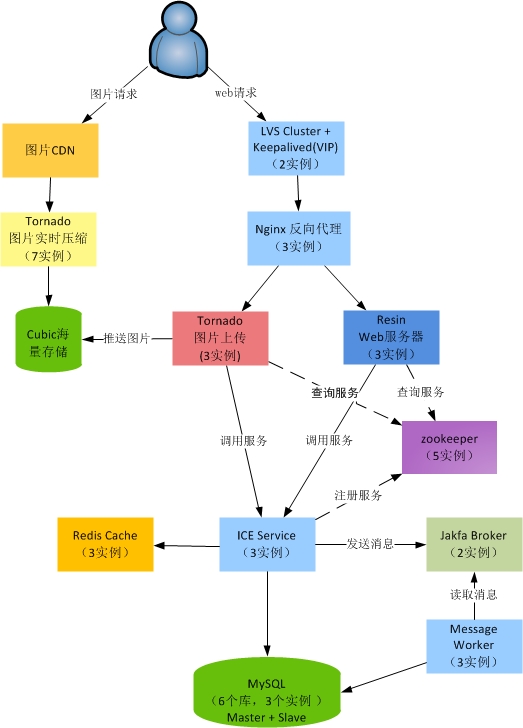
###1. 负载均衡 LVS + Keepalived
● 抗负载能力强(performance)
LVS工作方式的逻辑是非常之简单,而且工作在网络4层仅做请求分发之用,没有流量的转发。 相比nginx而言有更强的并发能力,默认配置能支持到10万并发
● 可伸缩性(scalability)
当服务的负载增长时,为获得更高的吞吐量,在LVS中增加real-servers来满足需求,其开销只是线性增长,且不降低服务质量。
● 高可用性(availability)
keepalived 可以实现服务器池对象的健康检查,负载均衡之间的自动失败切换(failover).从而保证LVS负载均衡本身的高可性。如果LVS中某real-server由于需要升级或其它原因而停止服务,其退出以及恢复工作,并不会造成整个LVS对客户端服务的中断。(例如对nginx进行在线升级操作)
● 成本低廉(Low cost)
购买F5 BIG-IP 和 NetScalar 等硬件负载均衡交换机动则需要十几万甚至数十万人民币。而基于LVS最基本的需求就是两台普通服务器。
★如何保持session?
为了保证服务器的伸缩性,我们的服务器是无状态的,也就是任何一台web server 都可以被其它web server 替代。
我们采用了基于加密 cookie 的session 来保持用户的访问状态。(当然也可以采用LVS 的会话保持机制来解决这个问题。)
###2. RPC机制: ICE + Protobuf + Zookeeper
● ICE 支持多平台,跨语言(语言中立),支持主流的语言,如Java/C++/Python 等。支持多种协议(TCP/UDP/SSL),自带集群管理,异步和同步都支持,并且文档齐全。 ICE的使用局限性:由于语言中立的需要,不接受直接返回null值,我们使用返回一个NULL Object 解决;不支持方法重载,那就再起一个方法名吧;ICE服务端抛出的Runtime 异常将不能被客户端捕获,可以采用声明式异常或者自定义返回CodeMsg的方式解决。
● zookeeper 集群是一个去中心化的分布式集群,并且有watcher 机制,监听数据变更。可以作为分布式服务的配置与注册服务。
● protobuf 能够压缩数据量,高效编码、解码,减少网络传输 或 缓存层内存占用大小。 protobuf 原生不支持map,需要自定义结构体来实现,thrfit则可以原生支持map 等复杂结构。
★为什么是ICE 而不是thrift?
为什么是ICE 而不是thrift , 因为我们团队对ICE 比较熟悉并且有成功案例.
后续的改进中会考虑使用thrift ,可以和 tornado 无缝结合,很好的利用tornado 的异步特性。
###3. 图片处理服务:python + tornado
考虑到Java对图片压缩处理的效率低下,我们使用python 的 PIL (Python Imaging Library)来对图片进行压缩处理。
tornado 是facebook用于处理FriendFeed 的开源Web框架, 它是非阻塞式服务器,而且速度相当快。得利于其 非阻塞的方式和对 epoll 的运用,Tornado 每秒可以处理数以千计的连接,因此 Tornado 是实时 Web 服务的一个 理想框架。
###4. 利用好Cache 提升系统性能(节约每1ms)
● 依赖工具与数据说话,可监控与衡量的设计。
(通过Spring动态代理拦截产生日志,从而监控请求处理过程的每个方法的耗时,找出性能瓶颈)
● 尽可能的采用批量操作,一次性获取需要的全部数据。
(例如:利用redis 缓存的批量接口或pipeline,数据库jdbc的batch操作。)在获取feed 与专辑列表页面通过批量操作把几百次请求合并为几次请求,降低网络IO的开销,从耗时1秒多降低到10ms,性能提升了100倍。
● 切分好缓存的粒度,达到最佳的缓存利用率。
(把图片数据与图片的浏览数分开,把专辑图片id列表与图片对象缓存分开。)
● 只获取需要展现的数据。
(例如:在专辑列表页上需要展现专辑的4个小图,但并不需要获取这4个小图的浏览数信息,就减少不必要的请求与时间开销。)
● 短路逻辑优化。
优先考虑全部命中缓存的情况,直接获取数据,取不到或数据个数小于请求个数,再考虑数据抓取。
● 划分操作优先级。
主要操作优先执行,次要操作或耗时较长的操作通过发送消息队列,放到后台任务执行。
(例如:图片转存时,需要累计图片原作者的被转存数。)
● 提升程序中可并行的部分。
根据Amdahl定律,并发的性能受限于必须串行的比例。(例如:图片转存时,利用线程池并发请求云存储进行图片文件复制操作。)
● 建立多级的缓存。
页面层可以划分为好几个json请求,进行片断缓存,service 层可以将组织出来的视图数据进行缓存。(由于目前性能基本达标与缓存维护成本,这个暂末实施。)
通过以上原则,进行简单的优化后。基本上所有请求都在50ms 以内,90%请求响应时间在20ms 以内。
小结:以上所提到的优化措施都是在代码层面的优化,实际上优化应该先从产品需求、业务流程、系统架构上考虑,最后才是根据实际线上的监控日志,对频繁调用的耗时操作进行优化。
★ redis 那些事
● redis 我们没有配置持久化,redis 的持久化有可能导致CPU瞬间100%,从而产生较高的延迟。
● redis list 列表时的对象不支持LRU(或者类似MongoDB Caped Collection 的特性),或者可以借鉴花瓣网自己实现的redis.fpush 。
● 为了防止数据库没有内容时,频繁的穿透redis cache层,进行mysql数据库查询。@小小剑士 发明了 emptyable_list,即使数据库返回的列表是空的,仍然在redis 中建立一个标志位,说明已从数据库加载过数据,无需再去查询数据。
● 为了避免缓存失效时的雪崩效应,应该在加载数据时建立起一个分布式锁(可用memcached 或 zookeeper 实现),或者只是简单load 展现数据的情况可以让获取不到锁的请求线程直接返回,即使用户第一次没访问到数据,刷一下页面也就正常了。
● 期待redis 3.0 的cluster 功能。
###5. 数据库设计
用户信息不分表
用户所产生的图片、好友信息、新鲜事根据用户id 进行CRC32 Hash 分库分表。
★如何解决明星用户的粉丝数特别多,导致表的数据分布不均匀?
把用户的粉丝根据用户id 做shard后,再进行一次shard。 user –> user_followers_shard_map —> user_followers_data。
具体参见《Pinterest的数据库分片架构》
###6. 编写可维护性的代码—保持架构的简单
● 把握原好面向对象设计的原则。
Java 程序员应该了解的 10 个面向对象设计原则 http://www.iteye.com/news/24488
● 持续重构,编写可维护性的代码。
团队内部成员互相进行code-review, 重构那些看起来复杂晦涩的逻辑。
● 可测试性。
积极编写靠谱的单元测试,能够有效提升软件的质量。
这里非常感谢@小小剑士 童鞋对单元测试工作的推广与坚持。
● 编码规范。
简短的方法名,规范的命名规则。使代码逻辑更加清晰明了,代码更容易被别人读懂。更多内容请参考《代码大全》《重构》《代码整洁之道》
案例:
● 在原先处理redis 的缓存交互逻辑与 缓存业务逻辑耦合在一起,我们进行了单独的分离。使用XXXRedisDao 处理具体与Redis 交互的代码,简化了类的职责,XXXCachedDao 只负责缓存 与 数据库的逻辑部分。
● 原先每个ICE Service 层都编写着复杂的业务视图,例如展示一个图片需要这个图片的用户昵称、头像等业务逻辑。改造后的Service 层,只吐出业务的基本数据,如feed 中只包含photo_id 的字段,而最终需要展现的photo 其它信息,通过在web 层调用其它service 进行组装,并且可以根据不同的展现需要对业务视图进行复用或定制。
● 利用jafka 消息分发业务事件消息,解除强耦合。例如:新建用户的初始化设置,上传图片给好友发送Feed.
● 封装许多工具类或内部类,优先利用组合模式来实现,达到组件化模块化,整个架构更加清晰合理。
###7. 其它
我们使用了twitter 开放出来的 snowflake 来生成UUID.
使用supervisord 监控 tornado 的进程,从而保证系统的稳定性与可靠性。
在管理后台或广场推送等方面,使用了MongoDB 作为方便快捷的存储。
Web前端使用了jQuery,RequireJs,doT 等前端Javascript框架。
前端返回的json数据暂时没有做gzip,除chrome外浏览器端解压反而把dom ready 的时间变长。
使用git 进行源码管理,基于hudson + maven 进行持续集成和部署。
使用 facebook 开放出来的 scribe 进行日志收集。
使用开源工具Ganglia 和自己开发的支撑平台对在线服务进行监控与分析。
###8. 广告
我们在招聘,欢迎所有NB闪闪的 UI设计师、 Web前端工程师、Java工程师、Python工程师 加入我们!
联系邮箱:ryanchen@sohu-inc.com
欢迎使用我们的产品 http://pp.sohu.com ,或提出您的宝贵意见。
补充一下和朋友的讨论:
1. 为什么不用Nginx模块来处理和压缩上传的图片,会不会更快?
- 我们的图片上传是利用tornado 服务端接收的内存里进行处理,没有写文件,速度应该有保证。(未经实际测试)
- 除了处理图片上传压缩,还需要处理post 到云存储 或从云存储获取数据,调用ICE服务等业务逻辑。相比现有的nginx 图片压缩模块来说,需要进一步扩展。(淘宝就是nginx模块进行图片的压缩。)
- 团队成员普通对C++不熟悉,而用python开发,易于上手,也容易进行修改维护。
2. LVS 和 HAProxy 有何区别?
来自抚琴煮洒的Blog中有一段话:
HAProxy可以对Mysql读进行负载均衡,对后端的MySQL节点进行检测和负载均衡,不过在后端的MySQL slaves数量超过10台时性能不如LVS,所以我向大家推荐LVS+Keepalived。
原文:软件级负载均衡器(LVS/HAProxy/Nginx)的特点简介和对比 http://andrewyu.blog.51cto.com/1604432/697466
引用请教的同事的回答就是HAProxy的性能没有LVS好,具体本人未做过验证。
参考资料